Volley是google提供网络请求库,使用说明看这里。注:由于Android6.0把HttpClient去掉了,可能会编译不过,这时需要替换里面的常量,或者将对应的Module的sdk版本改成小于23(Android Studio)。
适用于数据量小的请求,因为通过http请求返回的内容不管多大都会被放到内存里面,内容过大容易OOM,如果是下载大文件的需求官方推荐使用DownloadManager,或者使用HttpURLConnnection读流写到文件里面。
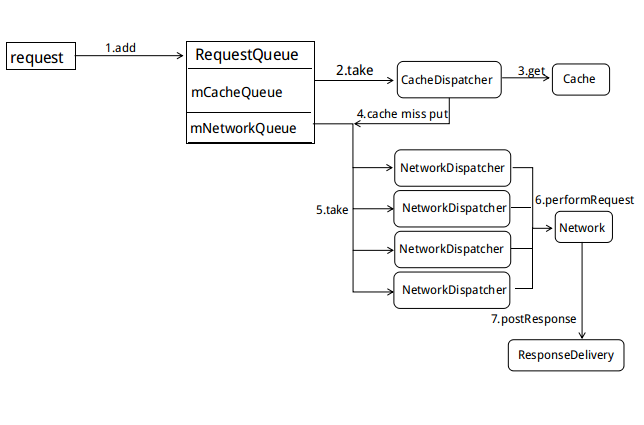
Volley大致工作流程如下:
通过向RequestQueue添加定制的Request发起请求,RequestQueue内部维护着两个优先级阻塞队列(PriorityBlockingQueue),分别用于触发缓存分发器(CacheDispatcher)与网络分发器处理(NetworkDispatcher)。
当一个请求到来时,如果请求不能被缓存,那么就会直接被添加放到mNetworkQueue里,request默认是可以缓存的,所以会先放到mCacheQueue,请求还没有到来之前CacheDispatcher是处于阻塞的状态,当向mCacheQueue添加Request时CacheDispatcher就会被唤醒并拿到这个Reuest,从缓存里面查询缓存,判断缓存是否存在并且有效,如果有效就会被直接交给ResponseDelivery进行结果响应,失效或者不存在就会把请求放到mNetworkQueue里。
同样,当请求没有来临之前NetworkDispatcher也是处于阻塞的状态,当一个网络请求被放到mNetworkQueue,NetworkDispatcher就会被唤醒并拿到这个Request,交给Network处理请求,得到结果Response,判断是否需要写入缓存,最后交给ResponseDelivery结果响应。
Volley处理请求流程就是一个生产者-消费者模式,我们生产Request请求,Dispatcher进行消费,然后进行结果分发。Volley的每个类职责都比较单一,并且很多都是基于抽象接口来实现,比如Request,缓存,处理请求的Network,具有很强的扩展性。下面分别对每个模块进行分析。
Request封装了一个HTTP请求,包含了请求的类型(GET OR POST OR …),请求的路径(url),HTTP请求的头部,POST请求的body等,我们可以根据HTTP协议结合实际需求定制HTTP请求。Request是一个泛型抽象类,我们需要实现如下两个方法,泛型表示响应结果类型。
public class Request<T> {
abstract protected Response<T> parseNetworkResponse(NetworkResponse response);
abstract protected void deliverResponse(T response);
//...
}
Request这两个抽象方法可以认为是Request的两个职责:
1.parseNetworkResponse需要Request自身从HTTP响应的二进制数据去解析需要的类型,NetworkReponse表示一个HTTP的响应结果里面包含了一下内容:
public final int statusCode;
public final byte[] data;
public final Map<String, String> headers;
public final boolean notModified;
public final long networkTimeMs;
一般情况下需要从data二进制数据里面解析出服务端返回的二进制数据,根据结合响应头部headers生成HTTP缓存Cache.Entry(已提供工具方法HttpHeaderParser # parseCacheHeaders),解析的过程是在Dispatcher线程里面调用的,也就是Work Thread,解析得到结果之后使用Response工厂方法产生正确的响应或者错误的响应:
public class Response {
public static <T> Response<T> success(T result, Cache.Entry cacheEntry) {
return new Response<T>(result, cacheEntry);
}
public static <T> Response<T> error(VolleyError error) {
return new Response<T>(error);
}
}
2.deliverResponse需要Request将响应结果内容分发,这里可以进一步调用接口分发,还可以直接更新UI,因为这里是通过Handler切换到UI线程调用的。
Request实现了Comparable接口,用于处理请求的优先级,每个请求被加入队列都会被分配一个递增序列mSequence实现FIFO,可以设置LOW,NORMAL,HIGH,IMMEDIATE四种优先级,默认优先级是NORMARL。
@Override
public int compareTo(Request<T> other) {
Priority left = this.getPriority();
Priority right = other.getPriority();
//先比较优先级,后比较加入的顺序
return left == right ?
this.mSequence - other.mSequence :
right.ordinal() - left.ordinal();
}
可以给Request设置一个RetryPolicy,表示Request的重试策略,请求失败之后的重试次数,请求等待的超时时间。
Volley给我们实现了五种Request,其中JsonRequest
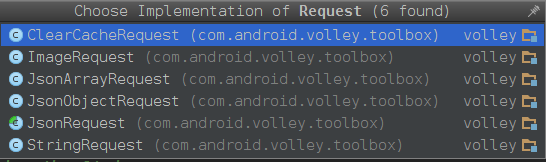
分别用于不同的响应结果String,JsonObject,JsonArray,Bitmap,有个比较特别,ClearCacheRequest清除缓存的请求,会被立刻执行。
Volley考虑到ImageRequest的特殊性做了特殊处理,例如优先级是最低的,并且为了防止OOM在统一时刻只解析一张图片,设置了重试策略。
RequestQueue#add,添加请求,内部维护了四个不同形式的集合,用于实现不同功能。
public class RequestQueue{
private final Map<String, Queue<Request<?>>> mWaitingRequests =
new HashMap<String, Queue<Request<?>>>();
private final Set<Request<?>> mCurrentRequests = new HashSet<Request<?>>();
private final PriorityBlockingQueue<Request<?>> mCacheQueue =
new PriorityBlockingQueue<Request<?>>();
private final PriorityBlockingQueue<Request<?>> mNetworkQueue =
new PriorityBlockingQueue<Request<?>>();
}
mCacheQueue和mNetworkQueue前面已经提到,用于触发NetworkDispatcher和CacheDispatcher处理请求。
mWaitingRequests:Request的key相同会被认为是相同的请求(key默认是Request的url),当有相同的请求到来时,如果Request是可以被缓存的(mShouldCache==true),那么,就会被放到mWaitingRequests中key对应的队列里,当请求被处理完成之后,Request会调用finish,通知将与之关联的RequestQueue将重复的Request全部放到mCacheQueue里处理,让CacheDispatcher从缓存里取出结果分发。如果Request不可缓存的,就会直接交给NetworkDispatcher处理。
mCurrentRequests:当一个请求被添加到RequestQueue相应也会就会被添加到mCurrentRequests,表示正在处理,可能在CacheDispatcher里面正等着被处理,或者在NetworkDispatcher里,等等,这个集合存在的目的就是让我们可以阻止队列中的Request进行下一步处理,因为在每一个阶段处理Request都会判断Request.isCanceled(),总之就是不会响应我们构造Request注册的回调。在Request被添加到RequestQueue之前,可以给Request设置一个tag(Object类型),要执行取消操作的时候调用RequestQueue#cancelAll(Object tag),就可以取消对应的Request,也可以自定义规则RequestFilter取消,使用tag取消也是RequestFilter实现的,规则就是tag的对象相等(对象地址)。
public void cancelAll(final Object tag) {
if (tag == null) {
throw new IllegalArgumentException("Cannot cancelAll with a null tag");
}
cancelAll(new RequestFilter() {
@Override
public boolean apply(Request<?> request) {
return request.getTag() == tag;
}
});
}
构造RequestQueue需要将抽象的接口Cache,Network,ResponseDelivery关联起来,因为内部的CacheDispatcher和NetworkDispatcher需要用到。要想让RequestQueue开始工作,需要把CacheDispatcher和NetworkDispatcher线程开启,当不在需要请求结束时最好停止这些线程。默认处理缓存分发的线程只有一个,处理网络分发的线程有四个。
public void start() {
stop();
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
另外如果要想要监听每一个Request的处理结果(可能是成功或者取消),可以向RequestQueue注册RequestFinishedListener。
public static interface RequestFinishedListener<T> {
/** Called when a request has finished processing. */
public void onRequestFinished(Request<T> request);
}
这应该是RequestQueue的所有工作了。
CacheDispatcher和NetworkDispatcher,开始工作后会处于循环,从相应的任务队列取出任务来处理。
CacheDispatcher从mCacheQueue取出Request之后,根据CacheKey从缓存里面取出缓存对象Cache.Entry,如果无效(不存在或者为空)就会放到mNetworkQueue里,交给NetworkDispatcher处理。命中缓存的话,调用前面Request实现的抽象接口parseNetworkResponse,从缓存对象里解析对应的数据对象和HTTP响应头部封装成一个Response,让ResponseDelivery去响应。
这里需要还有关键的一步,判断缓存对象是否需要刷新,从缓存头部会解析出来两个用于控制缓存是否有效的变量ttl和soft ttl。(Time To Live)
ttl小于当前的时间戳表示缓存已经完全失效不能再使用,这时就需要交给NetworkDispater处理,而soft ttl则表示缓存你暂时先用着,但还是要交给NetworkDispatcher处理,这次处理也比较特殊,会带上HTTP缓存信息相关头部,等它处理完这次请求才是真正的结束,并响应第二次更新缓存内容。
NetworkDispatcher的任务就是调用mNetwork执行真正的网络请求,解析之后解析HTTP响应,根据需要是否缓存。最后就是通知ResponseDelivery响应结果。
结束CacheDispatcher和NetworkDispatcher都是通过优先级阻塞队列(PriorityBlockingQueue)的take方法,当调用线程的interrupt方法,就会catch
InterruptedException,就可以比较“优雅”地结束掉线程的工作。另外CacheDispatcher往mNetworkQueue里放置Request的方法put也是阻塞的,但由于mNetworkQueue队列的容量是没有限制的,所以就不会被阻塞。
public interface Network {
public NetworkResponse performRequest(Request<?> request) throws VolleyError;
}
public interface HttpStack {
public HttpResponse performRequest(Request<?> request, Map<String, String> additionalHeaders)
throws IOException, AuthFailureError;
}
为了将耦合度降低,Volley将封装HTTP缓存响应头部,解析头部交给Network处理,响应状态码的处理,连接/等待超时的重试机制交给Network。真正请求的操作交给HttpStack,处理返回通用结果HttpResponse。两者的关系是Has-a(也就是聚合)。
Network只提供了一个实现 BasicNetwork。HttpStack提供了两种实现HurlStack,HttpClientStack,即内部实现分别是HttpUrlConnection和HttpClient。由于2.3的之前的版本HttpUrlConnection是不可靠的,所以默认使用的就是HttpClientStack,HttpUrlConnection的性能据说比HttpClient要好,并且后来Android 6.0也把HttpClient给剔除了,一般情况下还是使用HurlStack。我们也可以实现Network其他形式的请求栈,比如okhttp。
public static RequestQueue newRequestQueue(Context context, HttpStack stack) {
//...
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();
} else {
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
Network network = new BasicNetwork(stack);
return queue;
}
HttpStack的职责就是封装请求参数给对应的实现,比如HttpUrlConnection,然后读取响应结果再封装成NetworkResponse。里面也涉及到了有请求Url的重写, Https的相关处理。
在BasicNetwork中有一点也比较特别,将Http的实体内容(HttpEntity)解析为字节数组,将这些临时用到的字节数组放到一个对象池里面,使用结束之后又将其放回对象池,免去了字节数组对象的频繁初始化,抑制内存抖动和垃圾回收器频繁回收,提高性能,实现类是ByteArrayPool。
先来看ByteArrayPool的使用,就提供了两个接口,接口是同步的,因为分别有四个不同的NetworkDispatcher(线程)调用:
public class ByteArrayPool {
public synchronized void returnBuf(byte[] buf) {
//...
}
public synchronized byte[] getBuf(int len) {
//...
}
}
当我们需要使用byte[]的时候就通过调用getBuf获取,len为返回的byte数组大小,使用完毕之后调用returnBuf放回对象池里面。
下面是ByteArrayPool的结构:
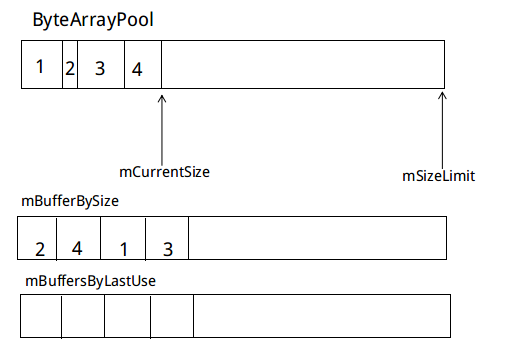
mBuffersBySize保存着池里面由小到大的引用,当我们需要一个对象的时候,就会从里面最小的开始查找,如果没有合适的对象,那么就直接new。
public synchronized byte[] getBuf(int len) {
for (int i = 0; i < mBuffersBySize.size(); i++) {
byte[] buf = mBuffersBySize.get(i);
if (buf.length >= len) {
mCurrentSize -= buf.length;
mBuffersBySize.remove(i);
mBuffersByLastUse.remove(buf);
return buf;
}
}
return new byte[len];
}
mBuffersByLastUse保存最近使用记录,最后被使用的会被添加到链表的尾部,当池里面的总大小超过mSizeLimit,就会从池子里面把最不常使用的移除,逐个移除,从第一个开始,直到满足小于等于mSizeLimit:
public synchronized void returnBuf(byte[] buf) {
if (buf == null || buf.length > mSizeLimit) {
return;
}
mBuffersByLastUse.add(buf);
int pos = Collections.binarySearch(mBuffersBySize, buf, BUF_COMPARATOR);
if (pos < 0) {
pos = -pos - 1;
}
mBuffersBySize.add(pos, buf);
mCurrentSize += buf.length;
trim();
}
private synchronized void trim() {
while (mCurrentSize > mSizeLimit) {
byte[] buf = mBuffersByLastUse.remove(0);
mBuffersBySize.remove(buf);
mCurrentSize -= buf.length;
}
}
Volley默认对象池里面的总大小为4K,所以比较适合小数据量的频繁请求,可以根据需求调整。
toolbox里与这个类有关系的就是PoolingByteArrayOutputStream,继承于ByteArrayOutputStream,ByteArrayOutputStream的核心就是内部有一个byte数组,通过往里面写内容实质就是往该数组写,里面的字节数组是通过new方式产生的,ByteArrayOutputStream不再使用就会被GC回收。
而PoolingByteArrayOutputStream内部的byte数组是从对象池里面取出来的,当使用结束之后又会放回到对象池里面。
public class PoolingByteArrayOutputStream extends ByteArrayOutputStream {
public PoolingByteArrayOutputStream(ByteArrayPool pool, int size) {
mPool = pool;
buf = mPool.getBuf(Math.max(size, DEFAULT_SIZE));
}
//...
@Override
public void close() throws IOException {
mPool.returnBuf(buf);
buf = null;
super.close();
}
}
当PoolingByteArrayOutputStream调用close的时候就是把其放回对象池里面。
最后再来看下总体的流程:
/** Reads the contents of HttpEntity into a byte[]. */
private byte[] entityToBytes(HttpEntity entity) throws IOException, ServerError {
PoolingByteArrayOutputStream bytes =
new PoolingByteArrayOutputStream(mPool, (int) entity.getContentLength());
byte[] buffer = null;
try {
InputStream in = entity.getContent();
if (in == null) {
throw new ServerError();
}
buffer = mPool.getBuf(1024);
int count;
while ((count = in.read(buffer)) != -1) {
bytes.write(buffer, 0, count);
}
return bytes.toByteArray();
} finally {
try {
// Close the InputStream and release the resources by "consuming the content".
entity.consumeContent();
} catch (IOException e) {
// This can happen if there was an exception above that left the entity in
// an invalid state.
VolleyLog.v("Error occured when calling consumingContent");
}
mPool.returnBuf(buffer);
bytes.close();
}
}
临时buffer和PoolingByteArrayOutputStream内部的byte[]都是来自对象池。
Cache是Volley提供的缓存接口,里面的接口也比较好理解:
public Entry get(String key);
public void put(String key, Entry entry);
public void initialize();
public void invalidate(String key, boolean fullExpire);
public void remove(String key);
public void clear();
缓存key为字符串,缓存项为Cache.Entry,里面包含HTTP响应内容的二进制内容,ETag,有效期等相关内容。Volley默认只提供了两种实现,基于磁盘文件的缓存DiskBasedCache,另外一个则是为了实现没有缓存功能的缓存NoCache,里面都是空实现。我们也可已根据自己的需求是实现缓存的方式,例如数据库缓存。
DiskBasedCache默认缓存大小为5MB,会把每一个缓存项当成一个文件,缓存项的格式如下:
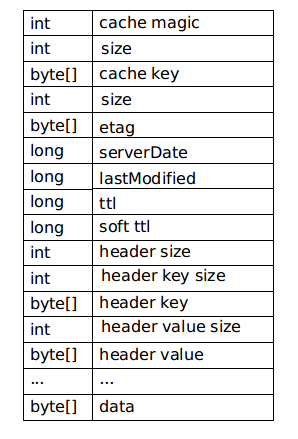
文件头写入的数据cache magic是用于标识该缓存文件的版本,当存入的和读取的cache magic会认为缓存无效而删除。存入字符串时会把其对应的UTF-8的二进制大小先存入,再存对应的数据。
byte[] data以上的内容为缓存CacheHeader,并且byte[] data没有对应的size,可以使用文件的大小减去CacheHeader的大小得到data的大小。
当CacheDispatcher开始工作时会执行缓存初始化操作,DiskBasedCache会将目录下的所有缓存文件载入,读取缓存文件的头部CacheHeader存入:
private final Map<String, CacheHeader> mEntries =
new LinkedHashMap<String, CacheHeader>(16, .75f, true);
第三个参数为accessOrder为true,访问内容会改变LinkedHashMap的entry顺序,最常访问的会被放到链表的后端。当放置新的缓存时,缓存总大小大于约定的总大小,那么就会移除某些缓存,就是从mEntries链表的前端开始移除。移除缓存就会把对应的文件删除和移除mEntries里面对应的CacheHeader,
ResponseDelivery用于当CacheDispatcher或NetworkDispatcher执行完某个请求,分发处理结果:
public interface ResponseDelivery {
public void postResponse(Request<?> request, Response<?> response);
public void postResponse(Request<?> request, Response<?> response, Runnable runnable);
public void postError(Request<?> request, VolleyError error);
}
Volley的默认实现是ExecutorDelivery:
public class ExecutorDelivery implements ResponseDelivery {
private final Executor mResponsePoster;
public ExecutorDelivery(final Handler handler) {
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
}
}
在RequestQueue里面,如果没有指定ResponseDelivery,那么初始化的就是参数为主线程Handler的ExecutorDelivery:
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
所以分发默认是在主线程里面执行的,其最终结果会向Request里分发:
if (mResponse.isSuccess()) {
mRequest.deliverResponse(mResponse.result);
} else {
mRequest.deliverError(mResponse.error);
}