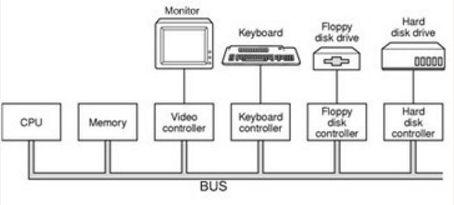
计算机的硬件设备中,最关键的三个部件:中央处理器CPU,内存和I/O控制芯片。
CPU与内存的的频率一样,直接连接到同一根总线(BUS)上,由于外部的I/O设备相比于内存与CPU有慢的比较多,所以每个设备都需要一个I/O控制器来协调设备与总线的通信。
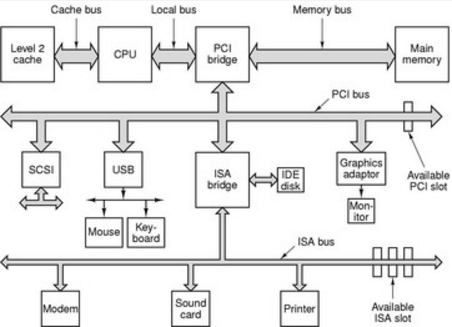
后来由于CPU的频率升高,导致内存跟不上CPU的速度,就产生了与内存频率一致的系统总线,即使这样内存相对于I/O设备还是属于高速频率,后来又出现高速的图形化设备为了让CPU,内存,高速化图形设备能够快速交换数据,就设计了一个叫北桥的芯片(Northbrige,PCI Brige)。北桥专门用来处理高速设备的通信,低速的I/O设备的通信就使用了南桥芯片(Southbrige,ISA brige)。
制造CPU的工艺方面已经达到了物理极限(4 GHz),就出现了多处理器的趋势。
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决
Any problem in computer science can be solved by another layer of indirection.
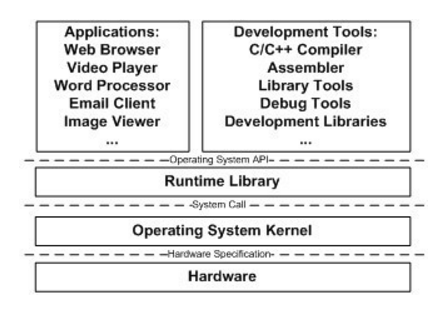
理论上只允许相邻层之间使用协议进行通信,层次结构保持不变,那么中间层只要保证接口不变,那么层就可以被方便地替换。除了应用程序与硬件,其他都是中间层,正是由于中间层的存在,才保证应用程序与硬件相对独立。
操作系统主要有两个功能:提供上层接口,管理硬件资源。硬件资源主要包括CPU,I/O设备,内存。
早期的多道程序(Multiprogramming),相当于是让任务顺序执行,这种调用方式粗糙,程序之间不分轻重缓急。后面又出现了分时系统(Time-Sharing System),每个程序在运行一小段时间之后交给其他程序执行,如果程序一直霸占着CPU,操作系统也没有办法,所以就出现了后面的抢占式(Preemptive),操作系统可以剥夺CPU资源将它分配给更需要的程序,如果操作系统分配给每个进程的时间都很短,CPU快速在多进程中切换,就出现了多个进程同时运行的假象。现代操作系统基本上都采用这种多任务的方式。
应用程序不需要也不能够与硬件直接打交道,只需调用操作系统提供的接口即可,然而硬件设备多如牛毛,操作的接口都不一样,不可能让操作系统为每一个硬件特殊处理,所以就加了驱动程序这一层,让硬件厂商根据操作系统提供的接口去实现,操作系统直接更驱动程序打交道即可。
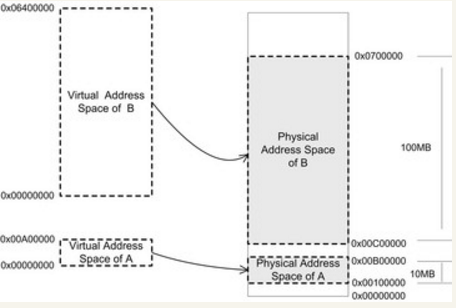
早期计算机程序都是直接运行在内存上面,即程序可以直接访问物理地址。地址空间不隔离会导致程序直接可以随便修改别人的内存里面的内容,当新的程序需要运行需要把其他程序数据放到磁盘,内存的使用效率低,程序运行地址不确定。
所以就加了中间层,虚拟地址(Virtul Address),操作系统通过映射策略,将每个程序虚拟地址映射到物理地址,保证物理地址不重叠,就能够达到地址空间隔离的效果,即进程隔离。
地址空间分两种:虚拟地址空间(Virtual Address Space)和物理地址空间(Physical Address Space)。
普通应用程序需要一个简单的执行环境,有自己的CPU,单一的地址空间好像自己占有了整个计算机,其实是运行在虚拟的地址空间。
早期的虚拟地址空间到物理地址空间的映射方式为分段(Segmentation),
这种方式存在一个问题,当新程序执行,内存不足时就会导致频繁地进行内存与磁盘数据置换,这种方式粒度较大,严重影响程序的执行效率,所以后面就出现了分页(Paging)的方式。
分页的基本方法是把地址空间人为地等分成固定大小的页,每一页的大小由硬件决定,或硬件支持多种大小的页,由操作系统选择决定页的大小。目前几乎所有的PC上的操作系统都使用4KB大小的页。
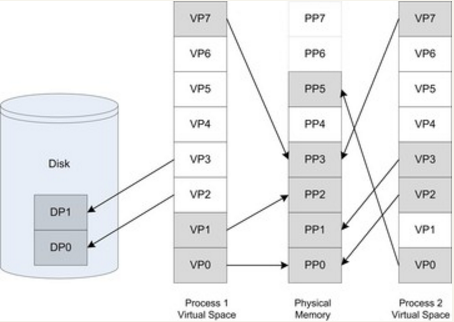
虚拟空间的页叫做虚拟页(VP,Visual Page),物理内存的页叫物理页(PP,Physical Page),磁盘中的页叫磁盘页(DP,Disk Page)。
Process 1的VP4,VP5,VP6处于未使用状态,VP2和VP3被映射到了磁盘页DP1,DP2,当进程需要访问VP2和VP3时,就会操作系统被加载到物理页,并建立映射关系。
虚拟地址空间的页被映射到同一地址空间就实现了内存共享,例如物理页PP3。
虚拟存储需要一个叫MMU(Memory Management Unit)的部件支持。

线程(Thread),有时被称为轻量级进程(Lightweight Process, LWP),是程序执行流的最小单元。一个标准的线程由线程ID、当前指令指针(PC)、寄存器集合和堆栈组成。
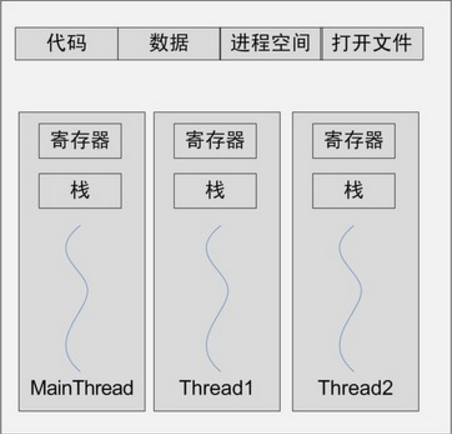
线程的私有存储空间包括栈,线程局部存储(Thread Local Storage,TLS),寄存器。
不论是在单处理器或者多处理器,线程总是并发执行的,当处理器数量大于线程数量,就是真正的并发执行。当处理器小于线程数量,比如在单任务的处理器中,线程的并发就是被模拟出来的,每个线程分配时间片(Time Slice)执行,快速地在CPU上切换。在线程调度(Thread Scheduler)中线程只是处于三种状态:
运行(Running):此时线程正在执行。
就绪(Ready):此时线程可以立刻运行,但CPU已经被占用。
等待(Waiting):此时线程正在等待某一事件(通常是I/O或同步)发生,无法执行。
线程的调度算法有优先级调度(Priority Schedule)和轮转法(Round Robin)。具有高优先级的会得到优先执行。
我们一般把频繁等待的线程称之为IO密集型线程(IO Bound Thread),而把很少等待的线程称为CPU密集型线程(CPU Bound Thread)。IO密集型线程总是比CPU密集型线程容易得到优先级的提升。
线程在用尽时间片之后会被强制剥夺继续执行的权利,而进入就绪状态,这个过程叫做抢占(Preemption)。